6 Linear Models and Regularization Methods
|
|

|
6.1 Subset Selection Methods
Some of the commands in this lab may take a while to run on your computer.
6.1.1 Best Subset Selection
Here we apply the best subset selection approach to the Hitters data. We wish to predict a baseball player’s Salary on the basis of various statistics associated with performance in the previous year.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
import itertools
import statsmodels.formula.api as smf
from mlxtend.feature_selection import ExhaustiveFeatureSelector as EFS
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
#import glmnet as gln
#from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.model_selection import train_test_split,KFold, cross_val_score
from sklearn.preprocessing import scale, StandardScaler
from sklearn.linear_model import LinearRegression, Ridge, RidgeCV, Lasso, LassoCV
from sklearn.decomposition import PCA
from sklearn.metrics import mean_squared_error
from sklearn.cross_decomposition import PLSRegression, PLSSVD
%matplotlib inline
plt.style.use('seaborn-white')
sns.set_context("notebook", font_scale=1.5, rc={"lines.linewidth": 2.5})First of all, we note that the Salary variable is missing for some of the players. The isnull() function can be used to identify the missing observations. It returns a vector of the same length as the input vector, with a True value for any elements that are missing, and a False value for non-missing elements. The sum() function can then be used to count all of the missing elements.
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).| AtBat | Hits | HmRun | Runs | RBI | Walks | Years | CAtBat | CHits | CHmRun | CRuns | CRBI | CWalks | League | Division | PutOuts | Assists | Errors | Salary | NewLeague | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 293 | 66 | 1 | 30 | 29 | 14 | 1 | 293 | 66 | 1 | 30 | 29 | 14 | A | E | 446 | 33 | 20 | NaN | A |
| 1 | 315 | 81 | 7 | 24 | 38 | 39 | 14 | 3449 | 835 | 69 | 321 | 414 | 375 | N | W | 632 | 43 | 10 | 475.0 | N |
| 2 | 479 | 130 | 18 | 66 | 72 | 76 | 3 | 1624 | 457 | 63 | 224 | 266 | 263 | A | W | 880 | 82 | 14 | 480.0 | A |
| 3 | 496 | 141 | 20 | 65 | 78 | 37 | 11 | 5628 | 1575 | 225 | 828 | 838 | 354 | N | E | 200 | 11 | 3 | 500.0 | N |
| 4 | 321 | 87 | 10 | 39 | 42 | 30 | 2 | 396 | 101 | 12 | 48 | 46 | 33 | N | E | 805 | 40 | 4 | 91.5 | N |
# Print the dimensions of the original Hitters data (322 rows x 20 columns)
print(Hitter.shape)
# Drop any rows the contain missing values
Hitter = Hitter.dropna()
# Print the dimensions of the modified Hitters data (263 rows x 20 columns)
print(Hitter.shape)
# One last check: should return 0
print(Hitter["Salary"].isnull().sum())
# Create dummy variables for qualitative features, since sklearn will not create dummy variables for categorical variables
qual = ['League', 'Division', 'NewLeague']
Hitter = pd.get_dummies(Hitter, columns=qual, drop_first=True)
Hitter.head()(322, 20)
(263, 20)
0| AtBat | Hits | HmRun | Runs | RBI | Walks | Years | CAtBat | CHits | CHmRun | CRuns | CRBI | CWalks | PutOuts | Assists | Errors | Salary | League_N | Division_W | NewLeague_N | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 315 | 81 | 7 | 24 | 38 | 39 | 14 | 3449 | 835 | 69 | 321 | 414 | 375 | 632 | 43 | 10 | 475.0 | 1 | 1 | 1 |
| 2 | 479 | 130 | 18 | 66 | 72 | 76 | 3 | 1624 | 457 | 63 | 224 | 266 | 263 | 880 | 82 | 14 | 480.0 | 0 | 1 | 0 |
| 3 | 496 | 141 | 20 | 65 | 78 | 37 | 11 | 5628 | 1575 | 225 | 828 | 838 | 354 | 200 | 11 | 3 | 500.0 | 1 | 0 | 1 |
| 4 | 321 | 87 | 10 | 39 | 42 | 30 | 2 | 396 | 101 | 12 | 48 | 46 | 33 | 805 | 40 | 4 | 91.5 | 1 | 0 | 1 |
| 5 | 594 | 169 | 4 | 74 | 51 | 35 | 11 | 4408 | 1133 | 19 | 501 | 336 | 194 | 282 | 421 | 25 | 750.0 | 0 | 1 | 0 |
The itertools.combinations function can help us to generate all possible combinations contains exactly k element within from a list of elements. We can then perform best subset selection by identifying the best model that contains a given number of predictors, where best is quantified using RSS. The following code implement the first stage of best subset selection.
def get_models(k_features, X, y):
"""
Fit all possible models that contain exactly k_features predictors.
X is predictor and y is target or response.
"""
n_features = X.shape[1]
X_combos = itertools.combinations(list(X.columns), k_features)
best_score = np.inf
for X_label in X_combos:
X_smf = ' + '.join(X_label)
f = 'Salary ~ {}'.format(X_smf)
# Fit model
lin_reg = smf.ols(formula=f, data=pd.concat([X, y], axis=1)).fit()
score = lin_reg.ssr
if score < best_score:
best_score, best_subset = score, X_label
best_reg = lin_reg
return best_score, best_reg, best_subsetWhich model with 2 predictors yields lowest RSS score?
X = Hitter.drop('Salary', axis=1) #19 variables remain
y = Hitter['Salary'] # put Salary as response variable
# Set number for predictors in subset
k = 2
# Get best models in subset
subset = get_models(2, X, y)
# Display results
print('This model yields the lowest RSS score for the subset of models with {} predictors:'.format(k))
print(subset)This model yields the lowest RSS score for the subset of models with 2 predictors:
(30646559.890372835, <statsmodels.regression.linear_model.RegressionResultsWrapper object at 0x7f81074d46d0>, ('Hits', 'CRBI'))First we fit all possible models in each subset of models with \(k\) predictors. This turns out to be a very computationally expensive process as number of possible combinations without repetition is given by:
\(\frac{p!}{k!(p-k)!}\)
Where \(p\) is number of predictors to choose from and we choose \(k\) of them.
# get all model results
rss = []
sub = []
reg = []
kft = []
for i in range(1,5):
best_score, best_reg, best_subset = get_models(i, X, y)
rss.append(best_score)
sub.append(best_subset)
reg.append(best_reg)
kft.append(i)
print('Progess: i = {}, done'.format(i))Progess: i = 1, done
Progess: i = 2, done
Progess: i = 3, done
Progess: i = 4, done| rss | reg | sub | |
|---|---|---|---|
| kft | |||
| 1 | 3.617968e+07 | <statsmodels.regression.linear_model.Regressio... | (CRBI,) |
| 2 | 3.064656e+07 | <statsmodels.regression.linear_model.Regressio... | (Hits, CRBI) |
| 3 | 2.924930e+07 | <statsmodels.regression.linear_model.Regressio... | (Hits, CRBI, PutOuts) |
| 4 | 2.797085e+07 | <statsmodels.regression.linear_model.Regressio... | (Hits, CRBI, PutOuts, Division_W) |
We can then choose the best model using different criteria.
plt.figure(figsize=(15,9))
plt.rcParams.update({'font.size': 14, 'lines.markersize': 10})
# Set up a 2x2 grid so we can look at 4 plots at once
plt.subplot(2, 2, 1)
# We will now plot a red dot to indicate the model with the largest adjusted R^2 statistic.
# The argmax() function can be used to identify the location of the maximum point of a vector
ax = sns.lineplot(x = "kft", y = "rss", data = results)
ax.set_xlabel('# Predictors')
ax.set_ylabel('RSS')
# We will now plot a red dot to indicate the model with the largest adjusted R^2 statistic.
# The argmax() function can be used to identify the location of the maximum point of a vector
results["rsquared_adj"] = results.apply(lambda row: row[1].rsquared_adj, axis=1)
plt.subplot(2, 2, 2)
ax = sns.lineplot(x = "kft", y = "rsquared_adj", data = results)
plt.plot(results["rsquared_adj"].argmax()+1, results["rsquared_adj"].max(), "or")
ax.set_xlabel('# Predictors')
ax.set_ylabel('adjusted rsquared')
# We'll do the same for AIC and BIC, this time looking for the models with the SMALLEST statistic
results["aic"] = results.apply(lambda row: row[1].aic, axis=1)
plt.subplot(2, 2, 3)
ax = sns.lineplot(x = "kft", y = "aic", data = results)
plt.plot(results["aic"].argmin()+1, results["aic"].min(), "or")
ax.set_xlabel('# Predictors')
ax.set_ylabel('AIC')
results["bic"] = results.apply(lambda row: row[1].bic, axis=1)
plt.subplot(2, 2, 4)
ax = sns.lineplot(x = "kft", y = "bic", data = results)
plt.plot(results["bic"].argmin()+1, results["bic"].min(), "or")
ax.set_xlabel('# Predictors')
ax.set_ylabel('BIC')Text(0, 0.5, 'BIC')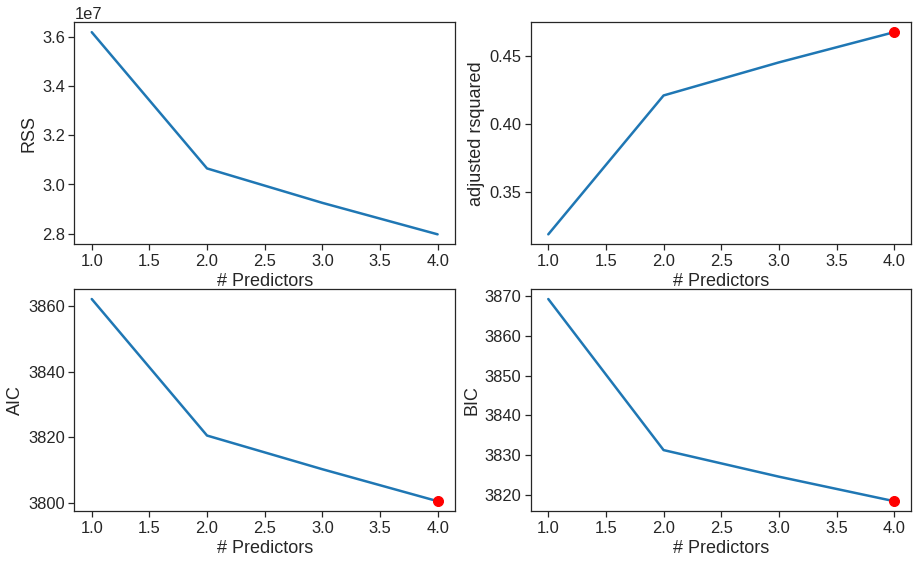
The package mlxtend can help us to perform feature selection, it internally use cross-validation to estimate test errors for all possible combinations of features instead of dividing the procedure into two stage
# Perform an Exhaustive Search. The EFS and SFS packages use 'neg_mean_squared_error'. The 'mean_squared_error' seems to have been deprecated. I think this is just the MSE with the a negative sign.
lr = LinearRegression()
efs1 = EFS(lr,
min_features=1,
max_features=4,
scoring='neg_mean_squared_error',
print_progress=True,
n_jobs=-1,
cv=5) #5-foldFeatures: 5035/5035ExhaustiveFeatureSelector(estimator=LinearRegression(),
feature_groups=[[0], [1], [2], [3], [4], [5], [6],
[7], [8], [9], [10], [11], [12], [13],
[14], [15], [16], [17], [18]],
max_features=4, n_jobs=-1,
scoring='neg_mean_squared_error')## This is a time consuming process, be careful. You may consider setting --ServerApp.iopub_msg_rate_limit to a larger value or not to execute this cell
r22 = []
sub = []
kft = []
for i in range(1,20):
efs1 = EFS(lr,
min_features=i,
max_features=i,
#scoring='neg_mean_squared_error', to calculate AIC, BIC you will need rss and the estimation of sigma (also from rss) https://xavierbourretsicotte.github.io/subset_selection.html
scoring='r2',
print_progress=True,
cv = 0, #no CV
n_jobs=-1) #parallelism
efs1.fit(X, y)
best_score, best_subset = efs1.best_score_, efs1.best_feature_names_
r22.append(best_score)
sub.append(best_subset)
kft.append(i)
print('Progess: i = {}, done'.format(i))Features: 19/19Progess: i = 1, doneFeatures: 171/171Progess: i = 2, doneFeatures: 969/969Progess: i = 3, doneFeatures: 3876/3876Progess: i = 4, doneFeatures: 11628/11628Progess: i = 5, doneFeatures: 27132/27132Progess: i = 6, doneFeatures: 50388/50388Progess: i = 7, doneFeatures: 75582/75582Progess: i = 8, doneFeatures: 92378/92378Progess: i = 9, doneFeatures: 92378/92378Progess: i = 10, doneFeatures: 75582/75582Progess: i = 11, doneFeatures: 50388/50388Progess: i = 12, doneFeatures: 27132/27132Progess: i = 13, doneFeatures: 11628/11628Progess: i = 14, doneFeatures: 3876/3876Progess: i = 15, doneFeatures: 969/969Progess: i = 16, doneFeatures: 18/19Progess: i = 17, doneFeatures: 1/1Progess: i = 18, done
Progess: i = 19, doneresults2 = pd.DataFrame({'kft': kft, 'r2': r22, 'sub': sub},
columns = ['r2', 'sub', 'kft']).set_index('kft')
results2['sub']kft
1 (CRBI,)
2 (Hits, CRBI)
3 (Hits, CRBI, PutOuts)
4 (Hits, CRBI, PutOuts, Division_W)
5 (AtBat, Hits, CRBI, PutOuts, Division_W)
6 (AtBat, Hits, Walks, CRBI, PutOuts, Division_W)
7 (Hits, Walks, CAtBat, CHits, CHmRun, PutOuts, ...
8 (AtBat, Hits, Walks, CHmRun, CRuns, CWalks, Pu...
9 (AtBat, Hits, Walks, CAtBat, CRuns, CRBI, CWal...
10 (AtBat, Hits, Walks, CAtBat, CRuns, CRBI, CWal...
11 (AtBat, Hits, Walks, CAtBat, CRuns, CRBI, CWal...
12 (AtBat, Hits, Runs, Walks, CAtBat, CRuns, CRBI...
13 (AtBat, Hits, Runs, Walks, CAtBat, CRuns, CRBI...
14 (AtBat, Hits, HmRun, Runs, Walks, CAtBat, CRun...
15 (AtBat, Hits, HmRun, Runs, Walks, CAtBat, CHit...
16 (AtBat, Hits, HmRun, Runs, RBI, Walks, CAtBat,...
17 (AtBat, Hits, HmRun, Runs, RBI, Walks, CAtBat,...
18 (AtBat, Hits, HmRun, Runs, RBI, Walks, Years, ...
19 (AtBat, Hits, HmRun, Runs, RBI, Walks, Years, ...
Name: sub, dtype: objectadj_r2 = np.array(adj_r2)
sns.lineplot(x=range(1,20), y=adj_r2)
plt.plot(adj_r2.argmax()+1, adj_r2.max(), "or")
plt.xticks(range(1,20))
plt.xlabel('# Predictors')
plt.ylabel('adjusted rsquared')Text(0, 0.5, 'adjusted rsquared')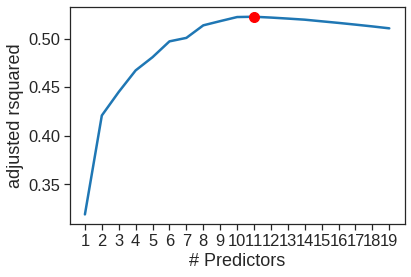
According to the adjusted \(R^2\), we see that the eleven-variable model is the best model. The predictor associated with the model is listed below.
6.1.2 Forward and Backward Stepwise Selection
In practice, the best subset is quite time-consuming, therefore forward or backward selection is usually prefered. Note that we do not consider null model below.
def forward(predictors):
# Pull out predictors we still need to process
remaining_predictors = [p for p in X.columns if p not in predictors]
results = []
for p in remaining_predictors:
results.append(processSubset(predictors+[p]))
# Wrap everything up in a nice dataframe
models = pd.DataFrame(results)
# Choose the model with the lowest RSS
best_model = models.loc[models['RSS'].argmin()]
# Return the best model, along with some other useful information about the model
return best_model
def backward(predictors):
results = []
for combo in itertools.combinations(predictors, len(predictors)-1):
results.append(processSubset(combo))
# Wrap everything up in a nice dataframe
models = pd.DataFrame(results)
# Choose the model with the lowest RSS
best_model = models.loc[models['RSS'].argmin()]
return best_modelmodels2 = pd.DataFrame(columns=['RSS', 'model'])
predictors = [] # we start with null model M0
for i in range(1,len(X.columns)+1):
models2.loc[i] = forward(predictors)
exog = models2.loc[i]['model'].model.exog_names.copy()
exog.remove('Intercept') #smf will automatically adds intercept
predictors = exog
print(i, predictors)1 ['CRBI']
2 ['CRBI', 'Hits']
3 ['CRBI', 'Hits', 'PutOuts']
4 ['CRBI', 'Hits', 'PutOuts', 'Division_W']
5 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat']
6 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks']
7 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks']
8 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns']
9 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat']
10 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat', 'Assists']
11 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat', 'Assists', 'League_N']
12 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat', 'Assists', 'League_N', 'Runs']
13 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat', 'Assists', 'League_N', 'Runs', 'Errors']
14 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat', 'Assists', 'League_N', 'Runs', 'Errors', 'HmRun']
15 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat', 'Assists', 'League_N', 'Runs', 'Errors', 'HmRun', 'CHits']
16 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat', 'Assists', 'League_N', 'Runs', 'Errors', 'HmRun', 'CHits', 'RBI']
17 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat', 'Assists', 'League_N', 'Runs', 'Errors', 'HmRun', 'CHits', 'RBI', 'NewLeague_N']
18 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat', 'Assists', 'League_N', 'Runs', 'Errors', 'HmRun', 'CHits', 'RBI', 'NewLeague_N', 'Years']
19 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns', 'CAtBat', 'Assists', 'League_N', 'Runs', 'Errors', 'HmRun', 'CHits', 'RBI', 'NewLeague_N', 'Years', 'CHmRun']We can then use AIC or BIC to choose the best model in the second stage
models3 = pd.DataFrame(columns=['RSS', 'model'], index = range(1, len(X.columns)))
predictors = X.columns # we start with full model Mp
models3.loc[len(predictors)] = processSubset(predictors)
while(len(predictors) > 1):
models3.loc[len(predictors)-1] = backward(predictors)
exog = models3.loc[len(predictors)-1]['model'].model.exog_names.copy()
exog.remove('Intercept')
predictors = exog
print(len(predictors), predictors)18 ['AtBat', 'Hits', 'HmRun', 'Runs', 'RBI', 'Walks', 'Years', 'CAtBat', 'CHits', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Assists', 'Errors', 'League_N', 'Division_W', 'NewLeague_N']
17 ['AtBat', 'Hits', 'HmRun', 'Runs', 'RBI', 'Walks', 'CAtBat', 'CHits', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Assists', 'Errors', 'League_N', 'Division_W', 'NewLeague_N']
16 ['AtBat', 'Hits', 'HmRun', 'Runs', 'RBI', 'Walks', 'CAtBat', 'CHits', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Assists', 'Errors', 'League_N', 'Division_W']
15 ['AtBat', 'Hits', 'HmRun', 'Runs', 'Walks', 'CAtBat', 'CHits', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Assists', 'Errors', 'League_N', 'Division_W']
14 ['AtBat', 'Hits', 'HmRun', 'Runs', 'Walks', 'CAtBat', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Assists', 'Errors', 'League_N', 'Division_W']
13 ['AtBat', 'Hits', 'Runs', 'Walks', 'CAtBat', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Assists', 'Errors', 'League_N', 'Division_W']
12 ['AtBat', 'Hits', 'Runs', 'Walks', 'CAtBat', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Assists', 'League_N', 'Division_W']
11 ['AtBat', 'Hits', 'Walks', 'CAtBat', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Assists', 'League_N', 'Division_W']
10 ['AtBat', 'Hits', 'Walks', 'CAtBat', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Assists', 'Division_W']
9 ['AtBat', 'Hits', 'Walks', 'CAtBat', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Division_W']
8 ['AtBat', 'Hits', 'Walks', 'CRuns', 'CRBI', 'CWalks', 'PutOuts', 'Division_W']
7 ['AtBat', 'Hits', 'Walks', 'CRuns', 'CWalks', 'PutOuts', 'Division_W']
6 ['AtBat', 'Hits', 'Walks', 'CRuns', 'PutOuts', 'Division_W']
5 ['AtBat', 'Hits', 'Walks', 'CRuns', 'PutOuts']
4 ['AtBat', 'Hits', 'CRuns', 'PutOuts']
3 ['Hits', 'CRuns', 'PutOuts']
2 ['Hits', 'CRuns']
1 ['CRuns']We see that using forward stepwise selection, the best one-variable model contains only CRBI, and the best two-variable model additionally includes Hits. For this data, the best one-variable through six-variable models are each identical for best subset and forward selection. However, the best seven-variable models identified by forward stepwise selection, backward stepwise selection, and best subset selection are different.
print(results2['sub'][6]) #best subset
print(models2['model'][6].model.exog_names[1:]) # Do not print Intercept('AtBat', 'Hits', 'Walks', 'CRBI', 'PutOuts', 'Division_W')
['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks']print(results2['sub'][7])
print(models2['model'][7].model.exog_names[1:]) # Do not print Intercept
print(models3['model'][7].model.exog_names[1:])('Hits', 'Walks', 'CAtBat', 'CHits', 'CHmRun', 'PutOuts', 'Division_W')
['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks']
['AtBat', 'Hits', 'Walks', 'CRuns', 'CWalks', 'PutOuts', 'Division_W']There are also other feature selection methods available in sklearn https://scikit-learn.org/stable/modules/feature_selection.html and mlxtend http://rasbt.github.io/mlxtend/api_subpackages/mlxtend.feature_selection/
lr = LinearRegression()
sfs1 = SFS(lr,
k_features=19,
forward=True,
floating=False,
scoring='neg_mean_squared_error',
cv=5)
sfs1.fit(X, y)SequentialFeatureSelector(estimator=LinearRegression(), k_features=(19, 19),
scoring='neg_mean_squared_error')| feature_idx | cv_scores | avg_score | feature_names | ci_bound | std_dev | std_err | |
|---|---|---|---|---|---|---|---|
| 1 | (11,) | [-69552.92336716877, -213009.92207213468, -118... | -142142.865462 | (CRBI,) | 74428.969884 | 57908.267167 | 28954.133583 |
| 2 | (1, 11) | [-53798.49669675372, -163254.80704040316, -104... | -124277.839415 | (Hits, CRBI) | 67031.533473 | 52152.810324 | 26076.405162 |
| 3 | (1, 11, 17) | [-62163.905140527975, -153941.83393405456, -97... | -120082.156746 | (Hits, CRBI, Division_W) | 59591.942149 | 46364.555526 | 23182.277763 |
| 4 | (1, 11, 13, 17) | [-65576.39003922763, -141278.46897398788, -825... | -117217.983933 | (Hits, CRBI, PutOuts, Division_W) | 56263.230127 | 43774.704486 | 21887.352243 |
| 5 | (0, 1, 11, 13, 17) | [-64199.08545469596, -133171.50527159323, -836... | -114112.221253 | (AtBat, Hits, CRBI, PutOuts, Division_W) | 54818.569767 | 42650.709646 | 21325.354823 |
| 6 | (0, 1, 5, 11, 13, 17) | [-60075.53412214324, -132306.39833204867, -765... | -110162.261438 | (AtBat, Hits, Walks, CRBI, PutOuts, Division_W) | 57689.191989 | 44884.151259 | 22442.075629 |
| 7 | (0, 1, 3, 5, 11, 13, 17) | [-60330.25929006559, -132346.01741313486, -766... | -110553.231464 | (AtBat, Hits, Runs, Walks, CRBI, PutOuts, Divi... | 58252.099546 | 45322.112462 | 22661.056231 |
| 8 | (0, 1, 3, 5, 6, 11, 13, 17) | [-64303.54034551623, -130892.95408839498, -745... | -110934.554619 | (AtBat, Hits, Runs, Walks, Years, CRBI, PutOut... | 57911.784603 | 45057.335875 | 22528.667937 |
| 9 | (0, 1, 3, 5, 6, 10, 11, 13, 17) | [-63508.043800155414, -137971.21159579078, -75... | -111236.70073 | (AtBat, Hits, Runs, Walks, Years, CRuns, CRBI,... | 57344.878076 | 44616.263337 | 22308.131669 |
| 10 | (0, 1, 3, 5, 6, 10, 11, 12, 13, 17) | [-75371.33424690235, -128223.28240695987, -742... | -110021.54195 | (AtBat, Hits, Runs, Walks, Years, CRuns, CRBI,... | 52372.497258 | 40747.582133 | 20373.791066 |
| 11 | (0, 1, 3, 5, 6, 10, 11, 12, 13, 16, 17) | [-75554.06873028616, -129427.52046763463, -741... | -110792.912735 | (AtBat, Hits, Runs, Walks, Years, CRuns, CRBI,... | 52633.998179 | 40951.038733 | 20475.519367 |
| 12 | (0, 1, 3, 5, 6, 10, 11, 12, 13, 16, 17, 18) | [-75588.46350075006, -130320.07532800487, -754... | -111570.449036 | (AtBat, Hits, Runs, Walks, Years, CRuns, CRBI,... | 52803.480655 | 41082.901857 | 20541.450929 |
| 13 | (0, 1, 2, 3, 5, 6, 10, 11, 12, 13, 16, 17, 18) | [-75578.82866274133, -130098.48628552802, -797... | -112677.57758 | (AtBat, Hits, HmRun, Runs, Walks, Years, CRuns... | 51485.083739 | 40057.144267 | 20028.572133 |
| 14 | (0, 1, 2, 3, 4, 5, 6, 10, 11, 12, 13, 16, 17, 18) | [-75574.5961843588, -132822.10224589257, -8117... | -113601.744452 | (AtBat, Hits, HmRun, Runs, RBI, Walks, Years, ... | 51592.950752 | 40141.068467 | 20070.534233 |
| 15 | (0, 1, 2, 3, 4, 5, 6, 10, 11, 12, 13, 15, 16, ... | [-75795.22141743562, -132827.4310618751, -8116... | -115593.410667 | (AtBat, Hits, HmRun, Runs, RBI, Walks, Years, ... | 53008.106168 | 41242.107459 | 20621.053729 |
| 16 | (0, 1, 2, 3, 4, 5, 6, 10, 11, 12, 13, 14, 15, ... | [-77460.55999200376, -130968.8896155133, -8015... | -116290.756812 | (AtBat, Hits, HmRun, Runs, RBI, Walks, Years, ... | 51687.395454 | 40214.549654 | 20107.274827 |
| 17 | (0, 1, 2, 3, 4, 5, 6, 7, 10, 11, 12, 13, 14, 1... | [-74741.82159316978, -128751.90512264056, -799... | -118642.76362 | (AtBat, Hits, HmRun, Runs, RBI, Walks, Years, ... | 56165.48438 | 43698.654974 | 21849.327487 |
| 18 | (0, 1, 2, 3, 4, 5, 6, 7, 9, 10, 11, 12, 13, 14... | [-75598.10118706549, -128381.8825323173, -7998... | -118980.278688 | (AtBat, Hits, HmRun, Runs, RBI, Walks, Years, ... | 56546.558941 | 43995.143928 | 21997.571964 |
| 19 | (0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,... | [-76408.91409133923, -129937.76968228162, -799... | -121136.310318 | (AtBat, Hits, HmRun, Runs, RBI, Walks, Years, ... | 59785.432226 | 46515.09738 | 23257.54869 |
6.1.3 Choosing Among Models Using the Validation-Set Approach and Cross-Validation
We just saw that it is possible to choose among a set of models of different sizes using AIC, BIC, and adjusted \(R^2\) in the second stage. We will now consider how to do this using the validation set and cross-validation approaches.
In order for these approaches to yield accurate estimates of the test error, we must use only the training observations to perform all aspects of model-fitting—including variable selection. Therefore, the determination of which model of a given size is best must be made using only the training observations. This point is subtle but important. If the full data set is used to perform the best subset selection step, the validation set errors and cross-validation errors that we obtain will not be accurate estimates of the test error.
In order to use the validation set approach, we begin by splitting the observations into a training set and a test set. We also set a random seed so that the user will obtain the same training set/test set split.
def processSubset(X_label, X_train, y_train, X_test, y_test):
# Fit model on feature_set and calculate RSS
X_smf = ' + '.join(X_label)
f = 'Salary ~ {}'.format(X_smf)
# Fit model
lin_reg = smf.ols(formula=f, data=pd.concat([X_train, y_train], axis=1)).fit()
RSS = ((lin_reg.predict(X_test[list(X_label)]) - y_test) ** 2).sum() #on test set
return {'model': lin_reg, 'RSS': RSS}def forward(predictors, X_train, y_train, X_test, y_test):
# Pull out predictors we still need to process
remaining_predictors = [p for p in X_train.columns if p not in predictors]
results = []
for p in remaining_predictors:
results.append(processSubset(predictors+[p], X_train, y_train, X_test, y_test))
# Wrap everything up in a nice dataframe
models = pd.DataFrame(results)
# Choose the model with the highest RSS
best_model = models.loc[models['RSS'].argmin()]
# Return the best model, along with some other useful information about the model
return best_modelmodels_test = pd.DataFrame(columns=['RSS', 'model'])
predictors = []
for i in range(1,len(X.columns)+1):
models_test.loc[i] = forward(predictors, X_train, y_train, X_test, y_test)
exog = models_test.loc[i]['model'].model.exog_names.copy()
exog.remove('Intercept')
predictors = exog
print(i, predictors)1 ['CRuns']
2 ['CRuns', 'Hits']
3 ['CRuns', 'Hits', 'Walks']
4 ['CRuns', 'Hits', 'Walks', 'CWalks']
5 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat']
6 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun']
7 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years']
8 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat']
9 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists']
10 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists', 'HmRun']
11 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists', 'HmRun', 'Runs']
12 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists', 'HmRun', 'Runs', 'League_N']
13 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists', 'HmRun', 'Runs', 'League_N', 'NewLeague_N']
14 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists', 'HmRun', 'Runs', 'League_N', 'NewLeague_N', 'Errors']
15 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists', 'HmRun', 'Runs', 'League_N', 'NewLeague_N', 'Errors', 'Division_W']
16 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists', 'HmRun', 'Runs', 'League_N', 'NewLeague_N', 'Errors', 'Division_W', 'CRBI']
17 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists', 'HmRun', 'Runs', 'League_N', 'NewLeague_N', 'Errors', 'Division_W', 'CRBI', 'RBI']
18 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists', 'HmRun', 'Runs', 'League_N', 'NewLeague_N', 'Errors', 'Division_W', 'CRBI', 'RBI', 'PutOuts']
19 ['CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years', 'CAtBat', 'Assists', 'HmRun', 'Runs', 'League_N', 'NewLeague_N', 'Errors', 'Division_W', 'CRBI', 'RBI', 'PutOuts', 'CHits']sns.lineplot(x=range(1,20), y=models_test['RSS'])
plt.xlabel('# Predictors')
plt.ylabel('RSS')
plt.plot(models_test['RSS'].argmin()+1, models_test['RSS'].min(), 'or')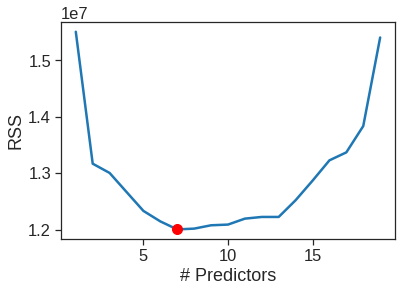
Now that we know what we’re looking for, let’s perform forward selection on the full dataset and select the best 7-predictor model. It is important that we make use of the full data set in order to obtain more accurate coefficient estimates. Note that we perform forward selection on the full data set and select the best 7-predictor model, rather than simply using the predictors that we obtained from the training set, because the best 7-predictor model on the full data set may differ from the corresponding model on the training set.
models_full = pd.DataFrame(columns=['RSS', 'model'])
predictors = []
for i in range(1,8):
models_full.loc[i] = forward(predictors, X, y, X, y) #use full dataset
exog = models_full.loc[i]['model'].model.exog_names.copy()
exog.remove('Intercept')
predictors = exog
print(i, predictors)1 ['CRBI']
2 ['CRBI', 'Hits']
3 ['CRBI', 'Hits', 'PutOuts']
4 ['CRBI', 'Hits', 'PutOuts', 'Division_W']
5 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat']
6 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks']
7 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks']print(models_test.loc[7, 'model'].model.exog_names)
print(models_full.loc[7, 'model'].model.exog_names) # we will use this one as our final model!['Intercept', 'CRuns', 'Hits', 'Walks', 'CWalks', 'AtBat', 'CHmRun', 'Years']
['Intercept', 'CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks']6.1.4 Model selection using Cross-Validation
Now let’s try to choose among the models of different sizes using cross-validation. This approach is somewhat involved, as we must perform forward selection within each of the \(k\) training sets. Despite this, we see that with its clever subsetting syntax, python makes this job quite easy. First, we create a vector that assigns each observation to one of \(k = 10\) folds, and we create a DataFrame in which we will store the results:
models_cv = pd.DataFrame(columns=["RSS", "model"])
j = 0
# Outer loop iterates over all folds
for train_index, test_index in kf.split(X):
j = j+1
# Reset predictors
predictors = []
X_train2, X_test2 = X.iloc[train_index], X.iloc[test_index]
y_train2, y_test2 = y.iloc[train_index], y.iloc[test_index]
# Inner loop iterates over each size i
for i in range(1,len(X.columns)+1):
# The perform forward selection on the full dataset minus the jth fold, test on jth fold
models_cv.loc[i] = forward(predictors, X_train2, y_train2, X_test2, y_test2)
# Save the cross-validated error for this fold
cv_errors[j][i] = models_cv.loc[i]["RSS"]
exog = models_cv.loc[i]['model'].model.exog_names.copy()
exog.remove('Intercept')
predictors = exogcv_mean = cv_errors.apply(np.mean, axis=1)
sns.lineplot(x=range(1,20), y=cv_mean)
plt.xlabel('# Predictors')
plt.ylabel('CV Error')
plt.plot(cv_mean.argmin()+1, cv_mean.min(), "or")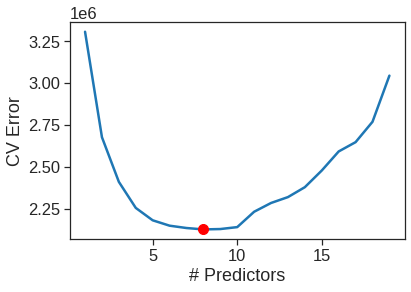
Cross-validation suggest 8-predictor model is the best model. We now perform best subset selection on the full data set in order to obtain the 8-variable model.
models_full = pd.DataFrame(columns=['RSS', 'model'])
predictors = []
for i in range(1,9):
models_full.loc[i] = forward(predictors, X, y, X, y) #use full dataset
exog = models_full.loc[i]['model'].model.exog_names.copy()
exog.remove('Intercept')
predictors = exog
print(i, predictors)1 ['CRBI']
2 ['CRBI', 'Hits']
3 ['CRBI', 'Hits', 'PutOuts']
4 ['CRBI', 'Hits', 'PutOuts', 'Division_W']
5 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat']
6 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks']
7 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks']
8 ['CRBI', 'Hits', 'PutOuts', 'Division_W', 'AtBat', 'Walks', 'CWalks', 'CRuns']There are also other supports from http://rasbt.github.io/mlxtend/user_guide/feature_selection/SequentialFeatureSelector/ and https://scikit-learn.org/stable/modules/feature_selection.html#feature-selection which implement different selection strategies.
6.2 Ridge Regression and the Lasso
The glmnet algorithms in R optimize the objective function using cyclical coordinate descent, while scikit-learn Ridge regression uses linear least squares with L2 regularization. They are rather different implementations, but the general principles are the same.
The glmnet() function in R optimizes: ### \[ \frac{1}{N}|| X\beta-y||^2_2+\lambda\bigg(\frac{1}{2}(1−\alpha)||\beta||^2_2 \ +\ \alpha||\beta||_1\bigg) \] (See R documentation and https://cran.r-project.org/web/packages/glmnet/vignettes/glmnet_beta.pdf)
The function supports L1 and L2 regularization. For just Ridge regression we need to use $= 0 $. This reduces the above cost function to ### \[ \frac{1}{N}|| X\beta-y||^2_2+\frac{1}{2}\lambda ||\beta||^2_2 \]
In python, you can also find similar functions in https://github.com/civisanalytics/python-glmnet
The sklearn Ridge() function on the other hand optimizes: ### \[ ||X\beta - y||^2_2 + \alpha ||\beta||^2_2 \] which is equivalent to optimizing ### \[ \frac{1}{N}||X\beta - y||^2_2 + \frac{\alpha}{N} ||\beta||^2_2 \]
By default the Ridge() function performs ridge regression for an automatically selected range of \(\alpha\) (or \(\lambda\) in the textbook) values. However, here we have chosen to implement the function over a grid of values ranging from \(\alpha=10^{10}\) to \(\alpha=10^{-2}\), essentially covering the full range of scenarios from the null model containing only the intercept, to the least squares fit. The following we plot 19 coefficients (excluding intercept) for 100 different alphas
alphas = 10**np.linspace(10,-2,100)
ridge = Ridge()
coefs = []
for a in alphas:
ridge.set_params(alpha=a)
ridge.fit(scale(X), y) # We standardize features before ridge regression
coefs.append(ridge.coef_)
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale('log')
ax.set_xlim(ax.get_xlim()[::-1]) # reverse axis
plt.axis('tight')
plt.xlabel('alpha')
plt.ylabel('weights')
plt.title('Ridge coefficients as a function of the regularization')Text(0.5, 1.0, 'Ridge coefficients as a function of the regularization')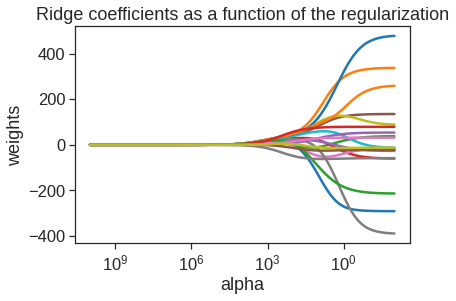
The above plot shows that the Ridge coefficients get larger when we decrease alpha. We now split the samples into a training set and a test set in order to estimate the test error of ridge regression and the lasso.
Note that if we had instead simply fit a model with just an intercept, we would have predicted each test observation using the mean of the training observations. In that case, we could compute the test set MSE like this:
We could also get similar result by fitting a ridge regression model with a very large value of \(\lambda\). Note that 1e10 means \(10^{10}\). This big penalty shrinks the coefficients to a very large degree and makes the model more biased, resulting in a higher MSE.
model = Ridge()
model.set_params(alpha=10**10)
X_scale = scaler.transform(X_train)
model.fit(X_scale, y_train)
X_scale_t = scaler.transform(X_test)
pred = model.predict(X_scale_t)
mean_squared_error(y_test, pred)172862.22059245987Next we fit a ridge regression model on the training set, and evaluate its MSE on the test set
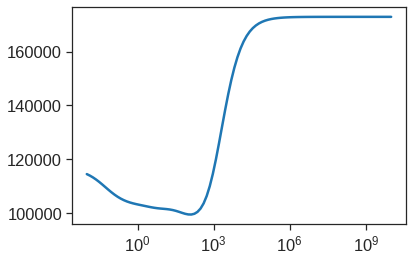
Therefore, we see that the value of alpha that results in the smallest cross-validation error is the 64th. What is the test MSE associated with this value of alpha?
We can also do built-in cross-validation using RidgeCV
kf = KFold(n_splits=10, shuffle=True, random_state=2)
ridgecv = RidgeCV(alphas=alphas, scoring='neg_mean_squared_error', cv=kf)
ridgecv.fit(X_scale, y_train)RidgeCV(alphas=array([1.00000000e+10, 7.56463328e+09, 5.72236766e+09, 4.32876128e+09,
3.27454916e+09, 2.47707636e+09, 1.87381742e+09, 1.41747416e+09,
1.07226722e+09, 8.11130831e+08, 6.13590727e+08, 4.64158883e+08,
3.51119173e+08, 2.65608778e+08, 2.00923300e+08, 1.51991108e+08,
1.14975700e+08, 8.69749003e+07, 6.57933225e+07, 4.97702356e+07,
3.76493581e+07, 2.84803587e+0...
2.00923300e+00, 1.51991108e+00, 1.14975700e+00, 8.69749003e-01,
6.57933225e-01, 4.97702356e-01, 3.76493581e-01, 2.84803587e-01,
2.15443469e-01, 1.62975083e-01, 1.23284674e-01, 9.32603347e-02,
7.05480231e-02, 5.33669923e-02, 4.03701726e-02, 3.05385551e-02,
2.31012970e-02, 1.74752840e-02, 1.32194115e-02, 1.00000000e-02]),
cv=KFold(n_splits=10, random_state=2, shuffle=True),
scoring='neg_mean_squared_error')model.set_params(alpha=ridgecv.alpha_)
model.fit(X_scale, y_train)
mean_squared_error(y_test, model.predict(X_scale_t))99586.568343827956.2.0.1 Fit model to full data set
AtBat -0.006619
Hits 49.467498
HmRun -0.859718
Runs 28.891970
RBI 22.425519
Walks 41.183554
Years -2.737654
CAtBat 24.915049
CHits 44.636902
CHmRun 38.851734
CRuns 45.225776
CRBI 47.320463
CWalks 3.558932
PutOuts 56.671318
Assists 7.335151
Errors -13.493719
League_N 14.878188
Division_W -48.564908
NewLeague_N 2.817544
dtype: float64As expected, none of the coefficients are zero—ridge regression does not perform variable selection!
You can also fit the ridge regression with LOOCV, this should be efficient since their is corresponding shortcut equation
ridgeloocv = RidgeCV(alphas=alphas, scoring='neg_mean_squared_error', gcv_mode='auto')
ridgeloocv.fit(X_scale, y_train)RidgeCV(alphas=array([1.00000000e+10, 7.56463328e+09, 5.72236766e+09, 4.32876128e+09,
3.27454916e+09, 2.47707636e+09, 1.87381742e+09, 1.41747416e+09,
1.07226722e+09, 8.11130831e+08, 6.13590727e+08, 4.64158883e+08,
3.51119173e+08, 2.65608778e+08, 2.00923300e+08, 1.51991108e+08,
1.14975700e+08, 8.69749003e+07, 6.57933225e+07, 4.97702356e+07,
3.76493581e+07, 2.84803587e+0...
2.00923300e+00, 1.51991108e+00, 1.14975700e+00, 8.69749003e-01,
6.57933225e-01, 4.97702356e-01, 3.76493581e-01, 2.84803587e-01,
2.15443469e-01, 1.62975083e-01, 1.23284674e-01, 9.32603347e-02,
7.05480231e-02, 5.33669923e-02, 4.03701726e-02, 3.05385551e-02,
2.31012970e-02, 1.74752840e-02, 1.32194115e-02, 1.00000000e-02]),
gcv_mode='auto', scoring='neg_mean_squared_error')6.2.1 The Lasso
We saw that ridge regression with a wise choice of alpha may outperform least squares as well as the null model on the Hitters data set. We now ask whether the lasso can yield either a more accurate or a more interpretable model than ridge regression. The following we plot 19 coefficients (excluding intercept) for 100 different alphas.
lasso = Lasso(max_iter=10000)
coefs = []
for a in alphas:
lasso.set_params(alpha=a)
lasso.fit(scale(X_train), y_train)
coefs.append(lasso.coef_)
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale('log')
ax.set_xlim(ax.get_xlim()[::-1]) # reverse axis
plt.axis('tight')
plt.xlabel('alpha')
plt.ylabel('weights')
plt.title('Lasso coefficients as a function of the regularization');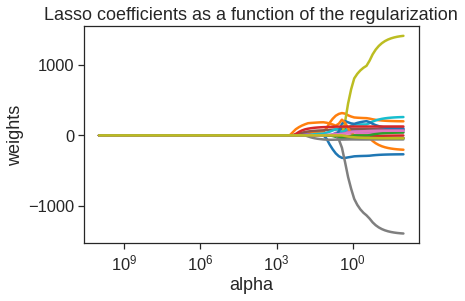
We can see from the coefficient plot that depending on the choice of tuning parameter, some of the coefficients will be exactly equal to zero. We now perform cross-validation and compute the associated test error.
kf = KFold(n_splits=10, shuffle=True, random_state=2)
lassocv = LassoCV(alphas=None, cv=kf, max_iter=10000)
lassocv.fit(X_scale, y_train.values.ravel())LassoCV(cv=KFold(n_splits=10, random_state=2, shuffle=True), max_iter=10000)lasso.set_params(alpha=lassocv.alpha_)
lasso.fit(X_scale, y_train)
mean_squared_error(y_test, lasso.predict(X_scale_t))104853.47279766494AtBat 0.000000
Hits 80.723891
HmRun 0.000000
Runs 0.000000
RBI 0.000000
Walks 45.833055
Years 0.000000
CAtBat 0.000000
CHits 0.000000
CHmRun 0.000000
CRuns 65.022016
CRBI 129.889483
CWalks 0.000000
PutOuts 55.241441
Assists -0.000000
Errors -0.000000
League_N 0.000000
Division_W -43.731588
NewLeague_N 0.000000
dtype: float64The test set MSE is very similar to the test MSE of ridge regression with \(\alpha\) chosen by cross-validation.
However, the lasso has a substantial advantage over ridge regression in that the resulting coefficient estimates are sparse. Here we see that 13 of the 19 coefficient estimates are exactly zero. So the lasso model with \(\alpha\) chosen by cross-validation contains only six variables.
6.3 PCR and PLS Regression
6.3.1 Principal Components Regression
Principal components regression (PCR) can be performed using the pca function. We now apply PCR to the Hitters data, in order to predict Salary. Again, we ensure that the missing values have been removed from the data, as described in Section 6.5.1.
pca = PCA()
X_reduced = pca.fit_transform(scale(X)) #standardize before PCA
print(pca.components_.shape)
pd.DataFrame(pca.components_.T).loc[:4,:5](19, 19)| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 0 | 0.198290 | -0.383784 | 0.088626 | 0.031967 | 0.028117 | -0.070646 |
| 1 | 0.195861 | -0.377271 | 0.074032 | 0.017982 | -0.004652 | -0.082240 |
| 2 | 0.204369 | -0.237136 | -0.216186 | -0.235831 | 0.077660 | -0.149646 |
| 3 | 0.198337 | -0.377721 | -0.017166 | -0.049942 | -0.038536 | -0.136660 |
| 4 | 0.235174 | -0.314531 | -0.073085 | -0.138985 | 0.024299 | -0.111675 |
(263, 19)| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 0 | -0.009649 | 1.870522 | 1.265145 | -0.935481 | 1.109636 | 1.211972 |
| 1 | 0.411434 | -2.429422 | -0.909193 | -0.264212 | 1.232031 | 1.826617 |
| 2 | 3.466822 | 0.825947 | 0.555469 | -1.616726 | -0.857488 | -1.028712 |
| 3 | -2.558317 | -0.230984 | 0.519642 | -2.176251 | -0.820301 | 1.491696 |
| 4 | 1.027702 | -1.573537 | 1.331382 | 3.494004 | 0.983427 | 0.513675 |
# Variance explained by the principal components
np.cumsum(np.round(pca.explained_variance_ratio_, decimals=4)*100)array([38.31, 60.15, 70.84, 79.03, 84.29, 88.63, 92.26, 94.96, 96.28,
97.25, 97.97, 98.64, 99.14, 99.46, 99.73, 99.88, 99.95, 99.98,
99.99])plt.plot(np.cumsum(pca.explained_variance_ratio_)) #scree plot
plt.xlabel('number of components')
plt.ylabel('cumulative explained variance');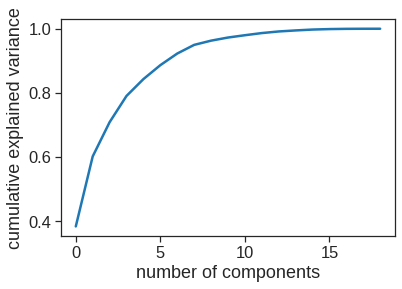
6.3.1.1 Fitting PCA with training data
In this method, we use the train/val/test split scheme like the lab in the textbook
pca2 = PCA()
X_reduced_train = pca2.fit_transform(X_scale)
n = len(X_reduced_train)
# 10-fold CV, with shuffle
kf_10 = KFold(n_splits=10, shuffle=True, random_state=2)
mse = []
regr = LinearRegression()
# Calculate MSE with only the intercept (no principal components in regression)
score = -1*cross_val_score(regr, np.ones((n,1)), y_train, cv=kf_10, scoring='neg_mean_squared_error').mean()
mse.append(score)
# Calculate MSE using CV for the 19 principle components, adding one component at the time.
for i in np.arange(1, 20):
score = -1*cross_val_score(regr, X_reduced_train[:,:i], y_train, cv=kf_10, scoring='neg_mean_squared_error').mean()
mse.append(score)
plt.plot(np.arange(0, 20), np.array(mse), '-v')
plt.xlabel('Number of principal components in regression')
plt.ylabel('MSE')
plt.title('Salary')
plt.xlim(xmin=-1);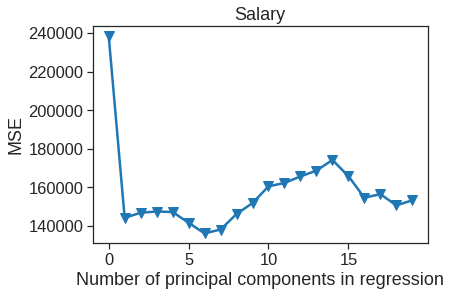
6.3.1.2 Transform test data with PCA loadings and fit regression on 6 principal components
6.3.2 Partial Least Squares
Scikit-learn PLSRegression gives same results as the pls package in R when using ‘method=’oscorespls’.
See documentation: http://scikit-learn.org/dev/modules/generated/sklearn.cross_decomposition.PLSRegression.html#sklearn.cross_decomposition.PLSRegression.
n = len(X_train)
# 10-fold CV, with shuffle
kf_10 = KFold(n_splits=10, shuffle=True, random_state=2)
mse = []
score = -1*cross_val_score(regr, np.ones((n,1)), y_train, cv=kf_10, scoring='neg_mean_squared_error').mean()
mse.append(score)
for i in np.arange(1, 20):
pls = PLSRegression(n_components=i)
score = -1*cross_val_score(pls, X_scale, y_train, cv=kf_10, scoring='neg_mean_squared_error').mean()
mse.append(score)
plt.plot(np.arange(0, 20), np.array(mse), '-v')
plt.xlabel('Number of principal components in regression')
plt.ylabel('MSE')
plt.title('Salary')
plt.xlim(xmin=-1);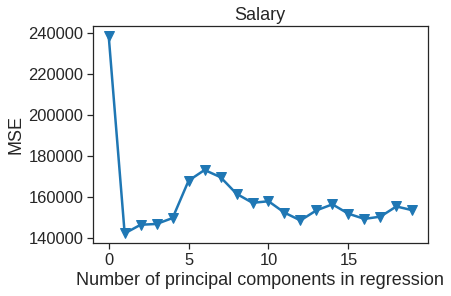
The lowest cross-validation error occurs when only \(M=1\) partial least squares directions are used. We now evaluate the corresponding test set MSE.