The following installation may take some time (~5min). If you do not want to run self-supervised learning you could comment out the first two packages.
Installing build dependencies ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 188.7/188.7 kB 6.8 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 88.2/88.2 kB 10.6 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 16.0 MB/s eta 0:00:00
Preparing metadata (setup.py) ... done
Building wheel for tensorflow-similarity (pyproject.toml) ... done
Building wheel for nmslib (setup.py) ... done
Building wheel for umap-learn (setup.py) ... done
Building wheel for pynndescent (setup.py) ... done
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 591.0/591.0 kB 26.5 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.1/7.1 MB 91.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 474.6/474.6 kB 43.4 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 81.4/81.4 kB 9.7 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 224.5/224.5 kB 23.6 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.8/7.8 MB 115.3 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 110.5/110.5 kB 14.8 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 212.5/212.5 kB 26.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 134.3/134.3 kB 17.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.0/1.0 MB 71.6 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 114.5/114.5 kB 15.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 268.8/268.8 kB 17.0 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 149.6/149.6 kB 17.7 MB/s eta 0:00:00
# Python ≥3.7 is recommendedimport sysassert sys.version_info >= (3, 7)# Scikit-Learn ≥1.01 is recommendedfrom packaging import versionimport sklearnassert version.parse(sklearn.__version__) >= version.parse("1.0.1")# Tensorflow ≥2.8.0 is recommendedimport tensorflow as tfassert version.parse(tf.__version__) >= version.parse("2.8.0")from tensorflow.keras.utils import image_dataset_from_directoryimport tensorflow_datasets as tfdsimport tensorflow_hub as hub# Self-supervised learning (Comment below if you do not want to train the SSL model)import tensorflow_similarity as tfsimimport tensorflow_addons as tfa# Fintune CLIP, BERT, GPTfrom transformers import pipelinefrom transformers import AutoProcessor, TFAutoModelForZeroShotImageClassificationfrom transformers import AutoTokenizer, TFAutoModelForSequenceClassification, TFAutoModelForCausalLMfrom transformers import BertTokenizerFast, AutoModelForCausalLMfrom transformers import TFAutoModelForSequenceClassificationfrom transformers import DataCollatorWithPaddingfrom transformers import create_optimizerfrom transformers.keras_callbacks import KerasMetricCallbackfrom transformers.keras_callbacks import PushToHubCallbackfrom datasets import load_datasetimport evaluate# Common importsimport numpy as npimport pandas as pdfrom pathlib import Pathimport randomimport timeimport osimport shutil, pathlibimport PIL.Image as Imageimport requests# To plot pretty figures%matplotlib inlineimport matplotlib as mplimport matplotlib.pyplot as pltmpl.rc('axes', labelsize=14)mpl.rc('xtick', labelsize=12)mpl.rc('ytick', labelsize=12)# to make this notebook's output stable across runsnp.random.seed(42)tf.random.set_seed(42)
/usr/local/lib/python3.10/dist-packages/tensorflow_addons/utils/tfa_eol_msg.py:23: UserWarning:
TensorFlow Addons (TFA) has ended development and introduction of new features.
TFA has entered a minimal maintenance and release mode until a planned end of life in May 2024.
Please modify downstream libraries to take dependencies from other repositories in our TensorFlow community (e.g. Keras, Keras-CV, and Keras-NLP).
For more information see: https://github.com/tensorflow/addons/issues/2807
warnings.warn(
ifnot tf.config.list_physical_devices('GPU'):print("No GPU was detected. Neural nets can be very slow without a GPU.")if"google.colab"in sys.modules:print("Go to Runtime > Change runtime and select a GPU hardware ""accelerator.")if"kaggle_secrets"in sys.modules:print("Go to Settings > Accelerator and select GPU.")
11.2 Transfer learning on a small dataset
Here we will use the dataset that we have introduced in Lab 9.
11.2.1 Downloading the data
The Dogs vs. Cats dataset that we will use isn’t packaged with Keras. It was made available by Kaggle as part of a computer vision competition in late 2013, back when convnets weren’t mainstream. You can download the original dataset from www.kaggle.com/c/dogs-vs-cats/data.
But you can also use Kaggle API. First, you need to create a Kaggle API key and download it to your local machine. Just navigate to the Kaggle website in a web browser, log in, and go to the My Account page. In your account settings, you’ll find an API section. Clicking the Create New API Token button will generate a kaggle.json key file and will download it to your machine.
# Upload the API’s key JSON file to your Colab# session by running the following code in a notebook cell:from google.colab import filesfiles.upload()
Finally, create a ~/.kaggle folder, and copy the key file to it. As a security best practice, you should also make sure that the file is only readable by the current user, yourself:
The first time you try to download the data, you may get a “403 Forbidden” error. That’s because you need to accept the terms associated with the dataset before you download it—you’ll have to go to www.kaggle.com/c/dogs-vs-cats/rules (while logged into your Kaggle account) and click the I Understand and Accept button. You only need to do this once.
!unzip -qq dogs-vs-cats.zip!unzip -qq train.zip
replace sampleSubmission.csv? [y]es, [n]o, [A]ll, [N]one, [r]ename: A
We now have 2,000 training images, 1,000 validation images, and 2,000 test images. Each split contains the same number of samples from each class: this is a balanced binary-classification problem, which means classification accuracy will be an appropriate measure of success.
Found 2000 files belonging to 2 classes.
Found 1000 files belonging to 2 classes.
Found 2000 files belonging to 2 classes.
Let’s look at the output of one of these Dataset objects: it yields batches of 180 × 180 RGB images (shape (32, 180, 180, 3)) and integer labels (shape (32,)). There are 32 samples in each batch (the batch size).
for data_batch, labels_batch in train_dataset:print("data batch shape:", data_batch.shape)print("labels batch shape:", labels_batch.shape)break
A common and highly effective approach to deep learning on small image datasets is to use a pretrained model. A pretrained model is a model that was previously trained on a large dataset, typically on a large-scale image-classification task. If this original dataset is large enough and general enough, the spatial hierarchy of features learned by the pretrained model can effectively act as a generic model of the visual world, and hence, its features can prove useful for many different computer vision problems, even though these new problems may involve completely different classes than those of the original task.
In this case, let’s consider a large convnet trained on the ImageNet dataset (1.2 million labeled images and 1,000 different classes). ImageNet contains many animal classes, including different species of cats and dogs, and you can thus expect it to perform well on the dogs-versus-cats classification problem. We’ll use the VGG16 architecturetrained on ImageNet, to extract interesting features from cat and dog images, and then train a dogs-versus-cats classifier on top of these features. The VGG16 model, among others, comes prepackaged with tf.Keras. You can import it from the tf.keras.applications module.
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58889256/58889256 [==============================] - 2s 0us/step
We pass three arguments to the constructor:
weights specifies the weight checkpoint from which to initialize the model.
include_top refers to including (or not) the densely connected classifier on top of the network. By default, this densely connected classifier corresponds to the 1,000 classes from ImageNet. Because we intend to use our own densely connected classifier (with only two classes: cat and dog), we don’t need to include it.
input_shape is the shape of the image tensors that we’ll feed to the network. This argument is purely optional: if we don’t pass it, the network will be able to process inputs of any size. Here we pass it so that we can visualize (in the following summary) how the size of the feature maps shrinks with each new convolution and pooling layer.
The final feature map has shape (5, 5, 512). That’s the feature map on top of which we’ll stick a densely connected classifier. At this point, there are two ways we could proceed:
Run the convolutional base over our dataset, record its output to a NumPy array on disk, and then use this data as input to a standalone, densely connected classifier. This solution is fast and cheap to run, because it only requires running the convolutional base once for every input image, and the convolutional base is by far the most expensive part of the pipeline. But for the same reason, this technique won’t allow us to use data augmentation.
Extend the model we have (conv_base) by adding Dense layers on top, and run the whole thing from end to end on the input data. This will allow us to use data augmentation, because every input image goes through the convolutional base every time it’s seen by the model. But for the same reason, this technique is far more expensive than the first.
11.2.3.1 Fast feature extration
We’ll start by extracting features as NumPy arrays by calling the predict() method of the conv_base model on our training, validation, and testing datasets. Let’s iterate over our datasets to extract the VGG16 features.
Importantly, predict() only expects images, not labels, but our current dataset yields batches that contain both images and their labels. Moreover, the VGG16 model expects inputs that are preprocessed with the function tf.keras.applications.vgg16.preprocess_input, which scales pixel values to an appropriate range.
train_features.shape
(2000, 5, 5, 512)
11.2.3.2 Defining and training the densely connected classifier
At this point, we can define our densely connected classifier (note the use of dropout for regularization) and train it on the data and labels that we just recorded.
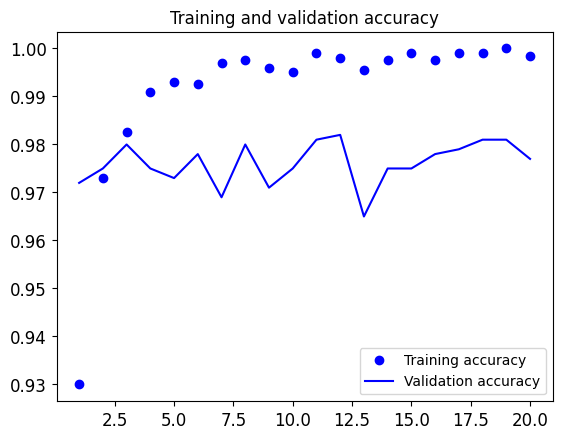
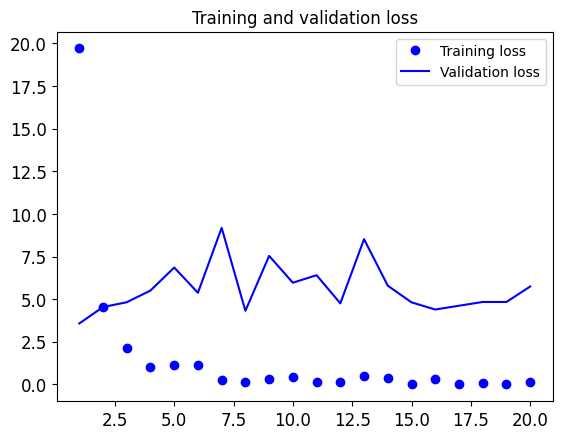
tf.keras.backend.clear_session()# 1. Define the model# Note the use of the Flatten layer before passing the# features to a Dense layer.inputs = tf.keras.Input(shape=(5, 5, 512))x = tf.keras.layers.Flatten()(inputs)x = tf.keras.layers.Dense(256)(x)x = tf.keras.layers.Dropout(0.5)(x)outputs = tf.keras.layers.Dense(1, activation="sigmoid")(x)# 2. Compile the modelmodel = tf.keras.Model(inputs, outputs)model.compile(loss="binary_crossentropy", optimizer="rmsprop", metrics=["accuracy"])model.summary()# 3. Train the modelcallbacks = [ tf.keras.callbacks.ModelCheckpoint( filepath="feature_extraction.keras", save_best_only=True, monitor="val_loss")]history = model.fit( train_features, train_labels, epochs=20, validation_data=(val_features, val_labels), callbacks=callbacks)
We reach a validation accuracy between 97%~98% — much better than we achieved in Lab 9 with the small model trained from scratch. This is a bit of an unfair comparison, however, because ImageNet contains many dog and cat instances, which means that our pretrained model already has the exact knowledge required for the task at hand. This won’t always be the case when you use pretrained features.
However, the plots also indicate that we’re overfitting almost from the start— despite using dropout with a fairly large rate. That’s because this technique doesn’t use data augmentation, which is essential for preventing overfitting with small image datasets.
11.2.4 Feature extraction together with data augmentation
Now let’s review the second technique for doing feature extraction, which is much slower and more expensive, but which allows us to use data augmentation during training: creating a model that chains the conv_base with a new dense classifier, and training it end to end on the inputs.
In order to do this, we will first freeze the convolutional base. Freezing a layer or set of layers means preventing their weights from being updated during training. If we don’t do this, the representations that were previously learned by the convolutional base will be modified during training. Because the Dense layers on top are randomly initialized, very large weight updates would be propagated through the network, effectively destroying the representations previously learned. In tf.Keras, we freeze a layer or model by setting its trainable attribute to False.
With this setup, only the weights from the two Dense layers that we added will be trained. That’s a total of four weight tensors: two per layer (the main weight matrix and the bias vector). Note that in order for these changes to take effect, you must first compile the model. If you ever modify weight trainability after compilation, you should then recompile the model, or these changes will be ignored.
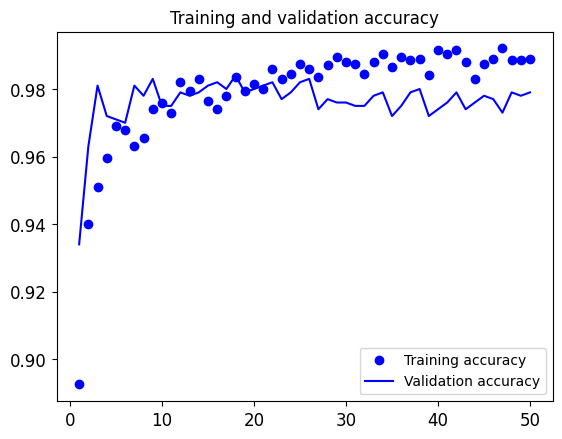
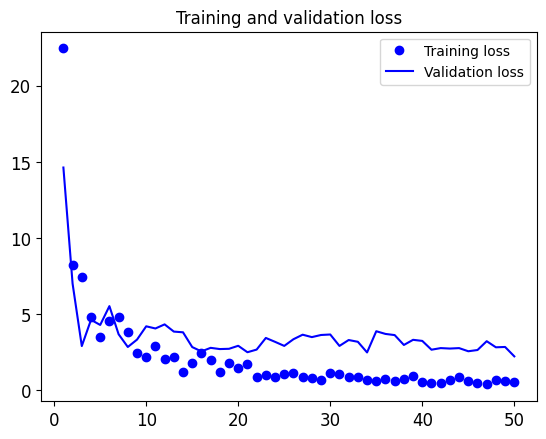
Let’s train our model. Thanks to data augmentation, it will take much longer for the model to start overfitting, so we can train for more epochs—let’s do 50.
We stated earlier that it’s necessary to freeze the convolution base of VGG16 in order to be able to train a randomly initialized classifier on top. For the same reason, it’s only possible to fine-tune the top layers of the convolutional base once the classifier on top has already been trained. If the classifier isn’t already trained, the error signal propagating through the network during training will be too large, and the representations previously learned by the layers being fine-tuned will be destroyed. Thus the steps for fine-tuning a network are as follows:
Add our custom network on top of an already-trained base network.
Freeze the base network.
Train the part we added.
Unfreeze some layers in the base network. (Note that usually you should not unfreeze “batch normalization” layers, which are not relevant here since there are no such layers in VGG16. Batch normalization and its impact on finetuning is explained in the lecture.)
Jointly train both these layers and the part we added.
You already completed the first three steps when doing feature extraction. Let’s proceed with step 4: we’ll unfreeze our conv_base and then freeze individual layers inside it.
We’ll fine-tune the last three convolutional layers, which means all layers up to block4_pool should be frozen, and the layers block5_conv1, block5_conv2, and block5_conv3 should be trainable.
conv_base.trainable =Truefor layer in conv_base.layers[:-4]: layer.trainable =False
Now we can begin fine-tuning the model. We’ll do this with the RMSprop optimizer, using a very low learning rate. The reason for using a low learning rate is that we want to limit the magnitude of the modifications we make to the representations of the three layers we’re fine-tuning. Updates that are too large may harm these representations.
Here, we get a test accuracy of 97.5%! By leveraging modern deep learning techniques, we managed to reach this result using only a small fraction of the training data that was available for the competition (about 10%). There is a huge difference between being able to train on 20,000 samples compared to 2,000 samples!
11.3 Using Tensorflow Hub
TensorFlow Hub is a repository of pre-trained TensorFlow models.
11.3.1 Download the classifier
Select a MobileNetV2 pre-trained model from TensorFlow Hub and wrap it as a tf.Keras layer with hub.KerasLayer. Any compatible image classifier model from TensorFlow Hub will work here, including the examples provided in the drop-down below.
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg
61306/61306 [==============================] - 0s 1us/step
Add a batch dimension (with np.newaxis) and pass the image to the model:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt
10484/10484 [==============================] - 0s 0us/step
11.3.2 Transfer learning
In this example, you will use the TensorFlow flowers dataset:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
228813984/228813984 [==============================] - 6s 0us/step
First, load this data into the model using the image data off disk with tf.keras.utils.image_dataset_from_directory(), which will generate a tf.data.Dataset:
Second, because TensorFlow Hub’s convention for image models is to expect float inputs in the [0, 1] range, use the tf.keras.layers.Rescaling() preprocessing layer to achieve this.
Third, finish the input pipeline by using buffered prefetching with Dataset.prefetch(), so you can yield the data from disk without I/O blocking issues.These are some of the most important tf.data methods you should use when loading data. Interested readers can learn more about them, as well as how to cache data to disk and other techniques, in the Better performance with the tf.data API guide.
Check how these predictions line up with the images:
plt.figure(figsize=(10,9))plt.subplots_adjust(hspace=0.5)for n inrange(30): plt.subplot(6,5,n+1) plt.imshow(image_batch[n]) plt.title(predicted_class_names[n]) plt.axis('off')_ = plt.suptitle("ImageNet predictions")
The results are far from perfect, but reasonable considering that these are not the classes the model was trained for (except for “daisy”).
11.3.2.2 Download the headless model
TensorFlow Hub also distributes models without the top classification layer. These can be used to easily perform transfer learning.
# Note that this time we select feature vector instead of classificationmobilenet_v2 ="https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4"feature_extractor_model = mobilenet_v2feature_extractor_layer = hub.KerasLayer( feature_extractor_model, input_shape=(224, 224, 3), trainable=False)
Create the feature extractor by wrapping the pre-trained model as a Keras layer with hub.KerasLayer. Use the trainable=False argument to freeze the variables, so that the training only modifies the new classifier layer:
model.compile( optimizer=tf.keras.optimizers.Adam(), loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # Note there are no softmax at the model metrics=['acc'])
11.4 Pretrain an image model with Self-supervised learning using SimSiam (Optional)
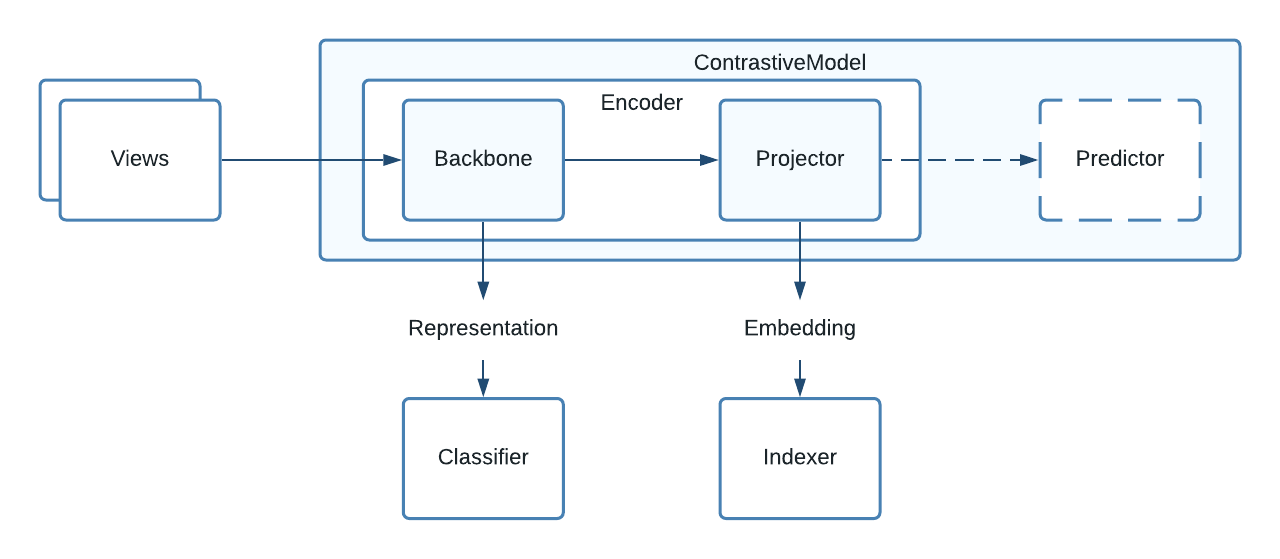
TensorFlow Similarity is a python package focused on making similarity learning and self-supervised learning quick and easy. Self-supervised learning is an approach to pre-training models using unlabeled data. The key insight is that you can train a self-supervised model to learn data representations by contrasting multiple augmented views of the same example. These learned representations capture data invariants, e.g., object translation, color jitter, noise, etc. Training a simple linear classifier on top of the frozen representations is easier and requires fewer labels because the pre-trained model already produces meaningful and generally useful features. Overall, self-supervised pre-training learns representations which are more generic and robust than other approaches to augmented training and pre-training.
Tensorflow Similarity provides a set of network architectures, losses, and data augmentations that are common across a number of self-supervised learning techniques. The Tensorflow Similarity package attempts to provide a consistent terminology across these techniques; however, this leads to slightly different naming conventions, as many papers use different terms to describe the same components. The main terms used by Tensorflow Similarity are:
View: A view represents an augmented example.
Backbone: Refers to the model that learns the Representation that we will use for downstream tasks.
Projector: Is an MLP model that projects the backbone representation of a view to an Embedding that is contrasted with other views using a specialized contrastive loss.
Predictor: Is an optional MLP model that is used, in conjunction with gradient stopping, in some recent architectures to further improve the representation quality.
Stop Gradient: Is used by some algorithms to ensure that we only propagate the update from the main view and not the contrasting view.
contrastive_model_terms.png
We will demonstrates how to use Tensorflow Similarity to boost classification accuracy by pre-training a ResNet18 model using contrastive learning on the cifar10 dataset. As you will see, the pre-trained model achieves about ~1.6x the accuracy of the model trained without pre-training. For example, using SimSiam pre-training, you can achieve 80% accuracy versus 50% accuracy when training the same architecture from scratch.
Creates the train, val, test, and query/index splits.
The TensorFlow Datasets’ CIFAR10 dataset provides a test and train split. However, we are going to partition the train data into the following additional splits:
Validation: Data used for validation metrics during the pre-training phase.
Query and Index: Data used to compute matching metrics. The query data is used to retrieve the nearest indexed examples.
In particular, the Query and Index split allows us to track the matching classification performance during training.
An increasing match accuracy is a strong indication that the model is learning useful features, however, it does require that we have labeled data. If a dataset only has a small number of labeled examples, they can be passed as the query and index to help monitor the potential matching classification performance during training.
Downloading and preparing dataset 162.17 MiB (download: 162.17 MiB, generated: 132.40 MiB, total: 294.58 MiB) to /root/tensorflow_datasets/cifar10/3.0.2...
Dataset cifar10 downloaded and prepared to /root/tensorflow_datasets/cifar10/3.0.2. Subsequent calls will reuse this data.
# Compute the indicies for query, index, val, and train splitsquery_idxs, index_idxs, val_idxs, train_idxs = [], [], [], []for cid inrange(ds_info.features["label"].num_classes): idxs = tf.random.shuffle(tf.where(y_raw_train == cid)) idxs = tf.reshape(idxs, (-1,)) query_idxs.extend(idxs[:200]) # 200 query examples per class index_idxs.extend(idxs[200:400]) # 200 index examples per class val_idxs.extend(idxs[400:500]) # 100 validation examples per class train_idxs.extend(idxs[500:]) # The remaining are used for trainingrandom.shuffle(query_idxs)random.shuffle(index_idxs)random.shuffle(val_idxs)random.shuffle(train_idxs)
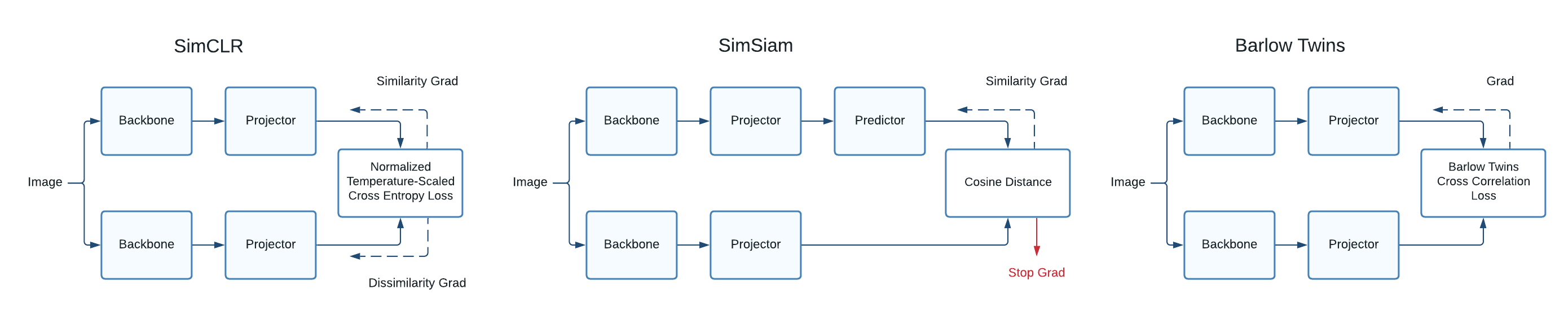
TensorFlow Similarity currently supports three different self-supervised models.
SimCLR: Only requires the Backbone and the projector and uses a contrastive cross-entropy loss.
SimSiam: Requires the Backbone, projector, and predictor and only compares the cosine distance between augmented views from the same example.
Barlow Twins: Only requires the Backbone and the projector and uses a loss that compares the feature covariance instead of contrasting the views.
VicReg: Only requires the Backbone and projector and uses a loss that enforces the learned representations to be invariant to random augmentations while preserving the covariance and variance information.
The ALGORITHM parameter is used throughout this notebook to set up the various architectures and the parameters defined below are set up to reproduce the results published in the papers.
CIFAR_IMG_SIZE =32BATCH_SIZE =512PRE_TRAIN_EPOCHS =200PRE_TRAIN_STEPS_PER_EPOCH =len(x_train) // BATCH_SIZEVAL_STEPS_PER_EPOCH =20WEIGHT_DECAY =5e-4DIM =2048# The layer size for the projector and predictor models.WARMUP_LR =0.0WARMUP_STEPS =0TEMPERATURE =Noneif ALGORITHM =="simsiam": INIT_LR =3e-2*int(BATCH_SIZE /256)elif ALGORITHM =="barlow": INIT_LR =1e-3# Initial LR for the learning rate schedule. WARMUP_STEPS =1000elif ALGORITHM =="simclr": INIT_LR =1e-3# Initial LR for the learning rate schedule, see section B.1 in the paper. TEMPERATURE =0.5# Tuned for CIFAR10, see section B.9 in the paper.elif ALGORITHM =="vicreg": INIT_LR =1e-3
11.4.2.2 Augmented View Configuration
Self-supervised networks require at least two augmented “views” of each example. This can be created using a DataSet and an augmentation function. The DataSet treats each example in the batch as its own class and then the augment function produces two separate views for each example.
This means the resulting batch will yield tuples containing the two views, i.e., Tuple[(BATCH_SIZE, 32, 32, 3), (BATCH_SIZE, 32, 32, 3)]. TensorFlow Similarity provides several random augmentation functions, and here we combine augmenters from the simCLR module to replicate the augmentations used in simsiam.
def img_scaling(img):return tf.keras.applications.imagenet_utils.preprocess_input( img, data_format=None, mode='torch')@tf.functiondef simsiam_augmenter(img, blur=True, area_range=(0.2, 1.0)):"""SimSiam augmenter. The SimSiam augmentations are based on the SimCLR augmentations, but have some important differences. * The crop area lower bound is 20% instead of 8%. * The color jitter and grayscale are applied separately instead of together. * The color jitter ranges are much smaller. * Blur is not applied for the cifar10 dataset. args: img: Single image tensor of shape (H, W, C) blur: If true, apply blur. Should be disabled for cifar10. area_range: The upper and lower bound of the random crop percentage. returns: A single image tensor of shape (H, W, C) with values between 0.0 and 1.0. """# random resize and crop. Increase the size before we crop. img = tfsim.augmenters.augmentation_utils.cropping.crop_and_resize( img, CIFAR_IMG_SIZE, CIFAR_IMG_SIZE, area_range=area_range )# The following transforms expect the data to be [0, 1] img /=255.# random color jitterdef _jitter_transform(x):return tfsim.augmenters.augmentation_utils.color_jitter.color_jitter_rand( x, np.random.uniform(0.0, 0.4), np.random.uniform(0.0, 0.4), np.random.uniform(0.0, 0.4), np.random.uniform(0.0, 0.1),"multiplicative", ) img = tfsim.augmenters.augmentation_utils.random_apply.random_apply(_jitter_transform, p=0.8, x=img)# # random grayscaledef _grascayle_transform(x):return tfsim.augmenters.augmentation_utils.color_jitter.to_grayscale(x) img = tfsim.augmenters.augmentation_utils.random_apply.random_apply(_grascayle_transform, p=0.2, x=img)# optional random gaussian blurif blur: img = tfsim.augmenters.augmentation_utils.blur.random_blur(img, p=0.5)# random horizontal flip img = tf.image.random_flip_left_right(img)# scale the data back to [0, 255] img = img *255. img = tf.clip_by_value(img, 0., 255.)return img@tf.function()def process(img): view1 = simsiam_augmenter(img, blur=False) view1 = img_scaling(view1) view2 = simsiam_augmenter(img, blur=False) view2 = img_scaling(view2)return (view1, view2)# Note that there is no label in the train_ds, instead the inputs are two views!train_ds = tf.data.Dataset.from_tensor_slices(x_train)train_ds = train_ds.repeat()train_ds = train_ds.shuffle(1024)train_ds = train_ds.map(process, num_parallel_calls=tf.data.AUTOTUNE)train_ds = train_ds.batch(BATCH_SIZE)train_ds = train_ds.prefetch(tf.data.AUTOTUNE)val_ds = tf.data.Dataset.from_tensor_slices(x_val)val_ds = val_ds.repeat()val_ds = val_ds.shuffle(1024)val_ds = val_ds.map(process, num_parallel_calls=tf.data.AUTOTUNE)val_ds = val_ds.batch(BATCH_SIZE)val_ds = val_ds.prefetch(tf.data.AUTOTUNE)
The following cell plots the pairs of augmented views side by side. This can be a useful sanity check as many augmentation functions are set up for the larger ImageNet examples and can be overly aggressive for smaller images found in CIFAR.
The following section creates the sub-models used by the different algorithms. There are various architectures for building self-supervised models which may include some of the following:
Backbone: This is the base model and is typically an existing architecture like ResNet or EfficientNet.
Projector: This is a small multi-layer Neural Net and provides the embedding features at the end of training.
Predictor: This model is used by BYOL and SimSiam and provides an additional small multi-layer Neural Net.
Typically, the projector and predictor networks are only 2 or 3 layers with batch normalization. Additionally, many papers show a single encoder block, but this often contains both the Backbone and the Projector network.
contrastive_loss_functions.png
The diagram above shows three self-supervised architectures supported by TensorFlow Similarity. As you can see, they all share a common structure: * Processing multiple views of the same example. * Using a backbone model for learning the representation output. * Using a projector for the embedding output. * Additionally, note that the loss is symmetric, so we compute it twice during each step. First for view 1 and then a second time for view 2. These two losses are then summed up to compute the final aggregate loss.
11.4.3.1 Backbone Model
The backbone uses a custom version of ResNet18 in order to reproduce the SimSiam CIFAR10 results.
The ResNet models provided in tf.keras.applications use larger [(1x1), (3x3), (1x1)] blocks that can’t be used to reproduce the SimSiam CIFAR10 results.
tf.keras.backend.clear_session()def get_backbone(img_size, activation="relu", preproc_mode="torch"): input_shape = (img_size, img_size, 3) backbone = tfsim.architectures.ResNet18Sim( input_shape, include_top=False, # Take the pooling layer as the output. pooling="avg", )return backbonebackbone = get_backbone(CIFAR_IMG_SIZE)backbone.summary()
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
This MLP is common to all the self-supervised models and is typically a stack of 3 layers of the same size. However, SimSiam only uses 2 layers for the smaller CIFAR images. Having too much capacity in the models can make it difficult for the loss to stabilize and converge. Additionally, the SimSiam paper found that disabling the center and scale parameters can lead to a small boost in the final loss.
Note this is the model output that is returned by ContrastiveModel.predict() and represents the distance based embedding. This embedding can be used for the KNN lookups and matching classification metrics. However, when using the pre-train model for downstream tasks, only the ContrastiveModel.backbone is used.
projector =None# Passing None will automatically build the default projector.
11.4.3.3 Predictor model
The predictor model is used by BYOL and SimSiam, and is an additional 2 layer MLP containing a bottleneck in the hidden layer.
predictor =None# Passing None will automatically build the default predictor.
11.4.4 Self-Supervised Algorithms
The following section builds the ContrastiveModel based on the ALGORITHM set at the start of the Notebook.
The model training is very sensitive to the learning rate decay and weight decay. * SimSiam: Requires using SGD with weight decay from TF Addons. Adding weight decay as a kernel_regularizer doesn’t seem to be able to reproduce the published results in the paper. * Barlow Twins: We can use LAMB and avoid the need for the learning rate schedule. Lamb is similar to the LARS optimizer used in the Barlow paper, but includes the use of ADAM. Alternatively, we can use SGD but the optimizer requires a warm up period, otherwise the loss explodes. * SimCLR: We can also use LAMB as the original paper uses LARS. However, LAMB seems to require smaller learning rates than shown for LARS in the original paper.
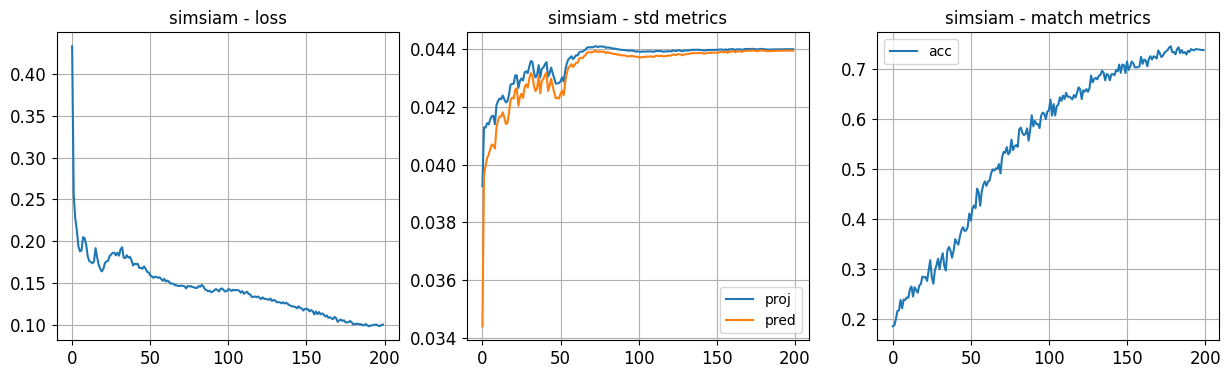
The model training provides a number of metrics. - loss: This represents the total loss over the contrastive batch. Separate contrastive and regularization losses will also be shown if there are trainable variables in the model layers. - proj_std and pred_std: These are added as metric logging layers in the model and show the std of the activations of the final layer in the projector or predictor models. - binary_accuracy: This is the nearest neighbor matching classification accuracy. A new index is built at the end of each epoch and the accuracy is computed using the query and index examples.
# The training wil take long time, you can reduce the epoch if you really want to trainhistory = contrastive_model.fit( train_ds, epochs=PRE_TRAIN_EPOCHS, steps_per_epoch=PRE_TRAIN_STEPS_PER_EPOCH, validation_data=val_ds, validation_steps=VAL_STEPS_PER_EPOCH, callbacks=[evb, mcp], verbose=1,)
The ContrastiveModel contains a set of sub-models and custom train and test steps. Consequently, the ContrastiveModel implements a custom save function that performs the following:
Saves each of the sub models, including the predictor if one exists.
A JSON file containing the serialized Loss, Metrics, and Optimizer.
WARNING:absl:Found untraced functions such as _jit_compiled_convolution_op, _jit_compiled_convolution_op, _jit_compiled_convolution_op, _jit_compiled_convolution_op, _jit_compiled_convolution_op while saving (showing 5 of 21). These functions will not be directly callable after loading.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704780) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706280) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705460) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706540) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706150) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705110) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704630) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706080) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705240) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706770) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706380) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705580) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705560) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704590) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706210) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705010) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706070) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706100) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705480) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706130) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705300) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704420) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706590) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706020) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706370) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704670) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706700) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704490) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706720) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704370) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705100) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704650) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705130) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704840) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704720) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706450) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705650) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705280) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705930) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706810) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706110) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706440) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704790) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704360) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705830) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706430) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704530) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704860) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706510) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706710) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705670) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705170) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705800) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705080) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705590) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706640) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704600) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704480) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706310) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706270) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706560) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705740) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704830) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706780) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705070) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705050) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705140) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704500) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704760) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706300) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706000) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704680) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704450) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705900) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706230) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706690) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705440) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706290) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705000) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704970) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706550) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705190) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704610) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706660) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705920) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705880) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706530) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704510) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706420) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704700) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706340) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704340) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705360) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704320) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706050) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705060) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705380) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706460) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705490) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705820) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705520) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705730) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705870) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705610) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706240) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706220) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705470) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705410) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706010) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704330) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706750) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704750) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706120) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705600) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705020) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706490) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704580) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706260) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705290) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705910) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705120) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704800) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704690) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706740) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704660) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706330) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706730) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705540) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705860) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706470) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706500) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704820) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706160) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705840) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704640) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704770) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704540) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704620) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704410) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705390) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704390) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704930) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704440) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705680) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706600) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704990) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704300) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705330) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706620) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706680) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706190) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706630) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705700) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704740) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705340) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704880) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705750) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706610) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706670) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705230) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706390) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705320) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705250) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705030) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705790) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705090) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706140) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704950) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705200) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706250) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705630) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705780) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706090) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705400) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705180) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704890) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706580) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706180) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706030) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706790) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704710) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705210) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706480) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704520) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704870) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704570) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704960) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705940) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704910) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705040) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706350) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705310) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706520) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704310) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706360) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704980) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704850) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704550) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705760) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704430) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705710) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704380) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704470) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706650) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705970) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706570) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706760) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705160) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706060) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706800) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704940) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704560) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705720) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705430) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705370) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705350) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705260) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705660) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706410) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705220) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706400) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706170) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706320) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705450) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704400) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705550) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705270) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705620) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706200) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705420) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705640) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705990) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704900) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705980) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704730) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4706040) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705530) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705950) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704810) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705150) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705510) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705890) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705960) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704350) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705850) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705690) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705500) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704460) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705770) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705570) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4705810) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
WARNING:absl:Importing a function (__inference_internal_grad_fn_4704920) with ops with unsaved custom gradients. Will likely fail if a gradient is requested.
11.4.5 Evaluation
This final section trains two different classifiers.
No Pre-training: Uses a ResNet18 model and a simple linear layer.
Pre-trained Uses the frozen pre-trained backbone from the ContrastiveModel and only trains the weights in the linear layer.
The original train data is partitioned into eval_train and eval_val splits and a simplified augmentation is applied to the training data. The models are then trained for 10 epochs and the classification accuracy is evaluated on the held out test split.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
WARNING:tensorflow:`tf.keras.layers.experimental.SyncBatchNormalization` endpoint is deprecated and will be removed in a future release. Please use `tf.keras.layers.BatchNormalization` with parameter `synchronized` set to True.
Zero-shot image classification is a task that involves classifying images into different categories using a model that was not explicitly trained on data containing labeled examples from those specific categories.
Traditionally, image classification requires training a model on a specific set of labeled images, and this model learns to “map” certain image features to labels. When there’s a need to use such model for a classification task that introduces a new set of labels, fine-tuning is required to “recalibrate” the model. In contrast, zero-shot or open vocabulary image classification models are typically multi-modal models that have been trained on a large dataset of images and associated descriptions. These models learn aligned vision-language representations that can be used for many downstream tasks including zero-shot image classification.
This is a more flexible approach to image classification that allows models to generalize to new and unseen categories without the need for additional training data and enables users to query images with free-form text descriptions of their target objects .
`text_config_dict` is provided which will be used to initialize `CLIPTextConfig`. The value `text_config["id2label"]` will be overriden.
All model checkpoint layers were used when initializing TFCLIPModel.
All the layers of TFCLIPModel were initialized from the model checkpoint at openai/clip-vit-large-patch14.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFCLIPModel for predictions without further training.
`text_config_dict` is provided which will be used to initialize `CLIPTextConfig`. The value `text_config["id2label"]` will be overriden.
Use the processor to prepare the inputs for the model. The processor combines an image processor that prepares the image for the model by resizing and normalizing it, and a tokenizer that takes care of the text inputs.
Pass the inputs through the model, and post-process the results:
outputs = model(**inputs)# Assuming that 'outputs' is a dictionary and 'logits_per_image' is a key that returns a batch of logitslogits = outputs['logits_per_image'][0]# Compute softmax probabilitiesprobs = tf.nn.softmax(logits, axis=-1).numpy()# Assuming that 'candidate_labels' is a list of labelsresult = [ {"score": float(score), "label": candidate_label}for score, candidate_label insorted(zip(probs, candidate_labels), key=lambda x: -x[0])]result
Feel free to swap out the sentence below for one of your own. However, leave [MASK] in somewhere to allow BERT to predict the missing word:
unmasker = pipeline('fill-mask', model='bert-base-uncased', framework="tf")unmasker("Artificial Intelligence [MASK] take over the world.")
All model checkpoint layers were used when initializing TFBertForMaskedLM.
All the layers of TFBertForMaskedLM were initialized from the model checkpoint at bert-base-uncased.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFBertForMaskedLM for predictions without further training.
[{'score': 0.3182392716407776,
'token': 2064,
'token_str': 'can',
'sequence': 'artificial intelligence can take over the world.'},
{'score': 0.18299587070941925,
'token': 2097,
'token_str': 'will',
'sequence': 'artificial intelligence will take over the world.'},
{'score': 0.056000713258981705,
'token': 2000,
'token_str': 'to',
'sequence': 'artificial intelligence to take over the world.'},
{'score': 0.04519489407539368,
'token': 2015,
'token_str': '##s',
'sequence': 'artificial intelligences take over the world.'},
{'score': 0.04515315219759941,
'token': 2052,
'token_str': 'would',
'sequence': 'artificial intelligence would take over the world.'}]
Text classification is a common NLP task that assigns a label or class to text. Some of the largest companies run text classification in production for a wide range of practical applications. One of the most popular forms of text classification is sentiment analysis.
This guide will show you how to:
Finetune DistilBERT on the IMDb dataset to determine whether a movie review is positive or negative.
Use your finetuned model for inference.
11.6.2.1 Load IMDb dataset
imdb = load_dataset("imdb")
Downloading and preparing dataset imdb/plain_text to /root/.cache/huggingface/datasets/imdb/plain_text/1.0.0/d613c88cf8fa3bab83b4ded3713f1f74830d1100e171db75bbddb80b3345c9c0...
Dataset imdb downloaded and prepared to /root/.cache/huggingface/datasets/imdb/plain_text/1.0.0/d613c88cf8fa3bab83b4ded3713f1f74830d1100e171db75bbddb80b3345c9c0. Subsequent calls will reuse this data.
Then take a look at an example:
imdb["test"][0]
{'text': 'I love sci-fi and am willing to put up with a lot. Sci-fi movies/TV are usually underfunded, under-appreciated and misunderstood. I tried to like this, I really did, but it is to good TV sci-fi as Babylon 5 is to Star Trek (the original). Silly prosthetics, cheap cardboard sets, stilted dialogues, CG that doesn\'t match the background, and painfully one-dimensional characters cannot be overcome with a \'sci-fi\' setting. (I\'m sure there are those of you out there who think Babylon 5 is good sci-fi TV. It\'s not. It\'s clichéd and uninspiring.) While US viewers might like emotion and character development, sci-fi is a genre that does not take itself seriously (cf. Star Trek). It may treat important issues, yet not as a serious philosophy. It\'s really difficult to care about the characters here as they are not simply foolish, just missing a spark of life. Their actions and reactions are wooden and predictable, often painful to watch. The makers of Earth KNOW it\'s rubbish as they have to always say "Gene Roddenberry\'s Earth..." otherwise people would not continue watching. Roddenberry\'s ashes must be turning in their orbit as this dull, cheap, poorly edited (watching it without advert breaks really brings this home) trudging Trabant of a show lumbers into space. Spoiler. So, kill off a main character. And then bring him back as another actor. Jeeez! Dallas all over again.',
'label': 0}
There are two fields in this dataset:
text: the movie review text.
label: a value that is either 0 for a negative review or 1 for a positive review.
11.6.2.2 Preprocess
The next step is to load a DistilBERT tokenizer to preprocess the text field:
To apply the preprocessing function over the entire dataset, use Datasets map function. You can speed up map by setting batched=True to process multiple elements of the dataset at once:
Now create a batch of examples using DataCollatorWithPadding. It’s more efficient to dynamically pad the sentences to the longest length in a batch during collation, instead of padding the whole dataset to the maximum length.
Including a metric during training is often helpful for evaluating your model’s performance. You can quickly load a evaluation method with the Evaluate library. For this task, load the accuracy metric (see the Evaluate quick tour to learn more about how to load and compute a metric). Then create a function that passes your predictions and labels to compute to calculate the accuracy:
If you aren’t familiar with finetuning a model with Keras, take a look at the basic tutorial here! To finetune a model in TensorFlow, start by setting up an optimizer function, learning rate schedule, and some training hyperparameters:
model = TFAutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased", num_labels=2, id2label=id2label, label2id=label2id)
Some layers from the model checkpoint at distilbert-base-uncased were not used when initializing TFDistilBertForSequenceClassification: ['activation_13', 'vocab_transform', 'vocab_layer_norm', 'vocab_projector']
- This IS expected if you are initializing TFDistilBertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing TFDistilBertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some layers of TFDistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['pre_classifier', 'classifier', 'dropout_19']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
You're using a DistilBertTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
No loss specified in compile() - the model's internal loss computation will be used as the loss. Don't panic - this is a common way to train TensorFlow models in Transformers! To disable this behaviour please pass a loss argument, or explicitly pass `loss=None` if you do not want your model to compute a loss.
The last two things to setup before you start training is to compute the accuracy from the predictions, and provide a way to push your model to the Hub. Both are done by using Keras callbacks. Pass your compute_metrics function to KerasMetricCallback.
To see how greedy search works, let’s start by loading the 1.5-billion-parameter version of GPT-2 with a language modeling head. we’ll use “Transformers are the” as the input prompt and run the decoding for eight timesteps. At each timestep, we pick out the model’s logits for the last token in the prompt and wrap them with a softmax to get a probability distribution. We then pick the next token with the highest probability, add it to the input sequence, and run the process again. The following code does the job, and also stores the five most probable tokens at each timestep so we can visualize the alternatives:
All model checkpoint layers were used when initializing TFGPT2LMHeadModel.
All the layers of TFGPT2LMHeadModel were initialized from the model checkpoint at gpt2-xl.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFGPT2LMHeadModel for predictions without further training.
Input
Choice 1
Choice 2
Choice 3
Choice 4
Choice 5
0
Transformers are the
most (8.54%)
only (4.96%)
best (4.66%)
Transformers (4.37%)
ultimate (2.16%)
1
Transformers are the most
popular (16.78%)
powerful (5.37%)
common (4.96%)
famous (3.71%)
successful (3.19%)
2
Transformers are the most popular
toy (10.62%)
toys (7.23%)
Transformers (6.60%)
of (5.46%)
and (3.76%)
3
Transformers are the most popular toy
line (34.39%)
in (18.20%)
of (11.71%)
brand (6.09%)
line (2.69%)
4
Transformers are the most popular toy line
in (46.27%)
of (15.10%)
, (4.94%)
on (4.40%)
ever (2.72%)
5
Transformers are the most popular toy line in
the (65.99%)
history (12.39%)
America (6.91%)
Japan (2.45%)
North (1.40%)
6
Transformers are the most popular toy line in the
world (69.24%)
United (4.56%)
history (4.29%)
US (4.23%)
U (2.30%)
7
Transformers are the most popular toy line in ...
, (39.73%)
. (30.64%)
and (9.87%)
with (2.32%)
today (1.74%)
Implementing greedy search wasn’t too hard, but we’ll want to use the built-in generate() function from Transformers to explore more sophisticated decoding methods. To reproduce our simple example, let’s make sure sampling is switched off (it’s off by default, unless the specific configuration of the model you are loading the checkpoint from states otherwise) and specify the max_new_tokens for the number of newly generated tokens:
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
========Generated Text==========
Transformers are the most popular toy line in the world, and the Transformers are the most popular toy line in the world.
The Transformers are the most popular toy line in the world, and the Transformers are the most popular toy line in the world.
Instead of decoding the token with the highest probability at each step, beam search keeps track of the top-b most probable next tokens:
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
========Generated Text==========
Transformers are the most popular toy line in the world, and they've been around for over 30 years, so it's no surprise that there are a lot of people who love them. But there are also a lot of people who don't like them.
The simplest sampling method is to randomly sample from the probability distribution of the model’s outputs over the full vocabulary at each timestep. By tuning T we can control the shape of the probability distribution when sampling. To see how we can use temperature to influence the generated text, let’s sample with T=2 by setting the temperature parameter in the generate() function:
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
========Generated Text==========
Transformers are the best.
I know. I know. I'm not saying that just because I'm a Transformers fan. I'm saying that because I'm a fan of the best toys. I'm a fan of the best action figures. I'm a
The idea behind top-k sampling is to avoid the low-probability choices by only sampling from the k tokens with the highest probability. This puts a fixed cut on the long tail of the distribution and ensures that we only sample from likely choices
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
========Generated Text==========
Transformers are the latest to be affected, with the Energon series in particular facing an imminent extinction at the hands of the G1 Transformer Prime Sentinel Prime.
I'm not much for reading, but I guess you can appreciate the significance of the number
We can also try chinese using the following model:
# casual language model (GPT2)import torchdevice ="cuda"if torch.cuda.is_available() else"cpu"tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')model = AutoModelForCausalLM.from_pretrained('ckiplab/gpt2-base-chinese').to(device) # or other models above
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:102 for open-end generation.
A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set `padding_side='left'` when initializing the tokenizer.